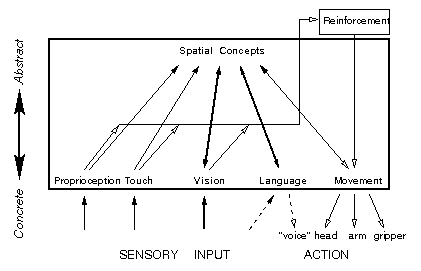
While we are currently focusing on vision and language and their interaction, the model should eventually bring together input from other perceptual domains -- proprioception and touch -- and from movement -- locomotion, the movement of a limb, and the manipulation of objects with a hand -- as well. The overall architecture we envision is shown in Figure 7.
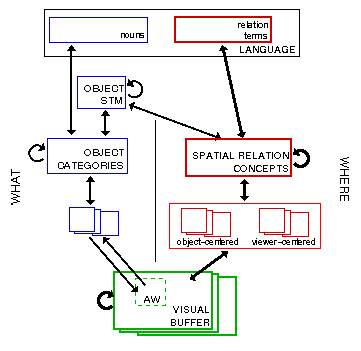
The visual component of Playpen is based loosely on Kosslyn's model of vision and imagery [Kosslyn, 1994]. Figure 8 shows how vision and language interact in the model.
The overall organization of the network is such that higher layers roughly preserve the spatial relations within lower layers; higher representations are more abstract than lower ones. The input visual layers, the Visual Buffer, are topological maps. The Visual Buffer performs bottom-up object segregation. The Attention Window is a mainly stimulus-driven mechanism which zooms in on a part of scene in the Visual Buffer corresponding roughly to a putative object. The Attention Window passes on a region in the Visual Buffer to the What system, which categorizes the object which is in the Attention Window, adding a representation of the object to an Object Short-Term Memory, a component not found in Kosslyn's model. The Where system receives the entire scene from the Visual Buffer. The segregation of the scene into regions associated with the different objects is preserved, but lower-level layers in this system are responsible for assigning perspective to the scene, both object-centered and viewer-centered, and higher-level layers extract salient dimensions such as position along the vertical dimension and object size. The representations provide input to the Spatial Relation Concepts layer, where the system categorizes spatial relations pre-linguistically. The Object Short-Term Memory and the Spatial Relation Concept layer interact so that it is possible for a relation together with its arguments to be represented, as is required, for example, for the meaning of a spatial relation expression.
The Language layer has units for two types of words, nouns and relation terms (prepositions in English). The What side of the visual system connects to the nouns, permitting labeling of objects and, in the comprehension direction, the understanding of nouns as visual patterns within the What system and the Visual Buffer. The Where side of the visual system connects to the relation terms, permitting labeling of relations and, in the comprehension direction, together with the What side, the understanding of relation expressions as visual patterns in the Where system and the Visual Buffer.