Obviously an overview of the human vision system is beyond the scope of this report. We will only be concerned here with what is most directly relevant to spatial relations. We follow closely Kosslyn's (1994)
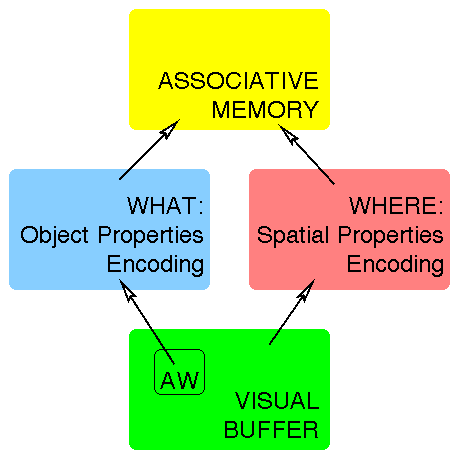
model of high-level vision and imagery because (1) it takes into account the whole range of subsystems that are involved in high-level vision and (2) it is meant to account for ``cognitive graphics'' as well as vision; that is, it also runs in the concepts-to-vision direction. The terms we use below are Kosslyn's. The components we are concerned with are illustrated in Figure 6.
It is generally agreed that the vision system divides into a subsystem responsible for What is in an observed scene and a subsystem responsible for Where the objects in the scene are. Among the tasks of the What system is the categorization of objects in the scene, a process which permits the assignment of noun labels to the objects. Similarly, the Where system categorizes relations between objects in the scene, a process which permits the assignment of relation terms to the relations in the scene. Thus both subsystems are crucial to the task we are interested in.
For our purposes, visual processing begins in a Visual Buffer (VB), a series of feature-specific maps which have already benefited from edge detection and region filling. The VB's task, among others, is to segregate the scene into regions associated with different objects.
The VB is scanned by an Attention Window (AW), which permits the system to focus on a single object at a time. The AW provides the interface between the VB and the What system, which extracts features spanning more than a ``pixel'' and ultimately categorizes the contents of the AW. The system operates not only in a bottom-up direction, however; there are top-down influences both on object categorization and on the placement of the AW.
On the Where side, output from the VB is assigned a 3D coordinate system, viewer-centered or object-centered (or both), and the location, size, and orientation of each object in the scene are extracted. Later the Where system is responsible for classifying the relations between objects in the scene. Relations are of two types, categorical relations (such as CONTAINMENT) and continuous relations (such as X-CENTIMETERS-FROM). As on the What side, categorization depends on top-down influences as well as on the strictly visual bottom-up ones.
At its ``top,'' the visual system makes contact with non-visual cognition in an Associative Memory (AM). Both the What and Where systems play a role in the AM and are in turn under its influence when there are top-down effects on object or relation categorization and when the system runs in the imagery direction. It is in this AM that vision and language come together.
Kosslyn (1994) has also amassed considerable evidence that mental images share many of the properties of actual percepts. For example, scanning a mental image takes time proportional to the distance between imaged objects. This evidence suggests that visual mental imagery and visual perception share mechanisms, that imagery amounts in a sense to running the vision system in reverse.
For our purposes, then, two points are important: