Each language provides speakers, hearers, and learners with a finite set of lexical items and structures to apply to a continuous world, and it is convenient to view a language as ``slicing up'' the world in a particular way. There seem to be both universal and language-specific aspects to the way this happens. All languages apparently make a fundamental distinction between nouns on the one hand and several classes of words on the other, most centrally, verbs. It has been argued [Langacker, 1987b], though not uncontroversially, that this distinction corresponds to a fundamental conceptual distinction between objects and relations.
The nouns of a language divide the world into categories of objects
and substances. Verbs, prepositions, and postpositions break things
down in a quite different way from nouns, singling out relations between the
objects which the nouns refer to.
Spatial relations are an important subcategory, and what is striking
here is the relatively small number of discrete spatial relation
categories that each language makes available.
The relation term itself may be a preposition, postposition,
verb, or even a noun inflection; morphological details will not
concern us further.
A complete spatial relation expression includes, in addition
to the relation term itself, two noun phrases, representing the thing
being related (the trajector) and the thing it is being related
to (the landmark).
The choice of trajector and landmark matters:
the stick is on the block does not mean the same thing as
the block is under the stick.
Trajector seems to correlate with the perceptual figure
[Herskovits, 1986, Langacker, 1987a].
Verbs, prepositions, and postpositions break things
down in a quite different way from nouns, singling out relations between the
objects which the nouns refer to.
Spatial relations are an important subcategory, and what is striking
here is the relatively small number of discrete spatial relation
categories that each language makes available.
The relation term itself may be a preposition, postposition,
verb, or even a noun inflection; morphological details will not
concern us further.
A complete spatial relation expression includes, in addition
to the relation term itself, two noun phrases, representing the thing
being related (the trajector) and the thing it is being related
to (the landmark).
The choice of trajector and landmark matters:
the stick is on the block does not mean the same thing as
the block is under the stick.
Trajector seems to correlate with the perceptual figure
[Herskovits, 1986, Langacker, 1987a].
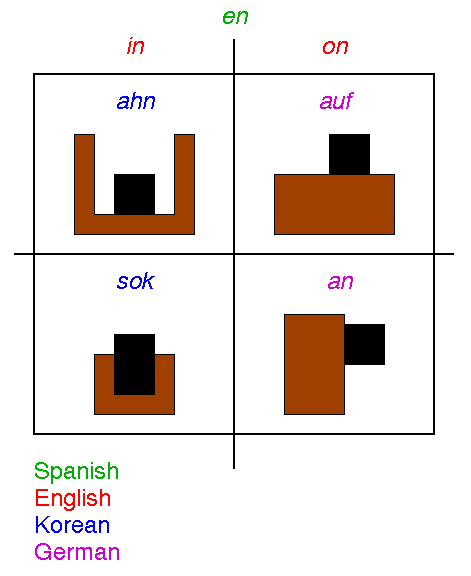
Even a cursory examination of the spatial relation expressions in a subset of languages reveals that the space of possible relations is sliced up in a variety of ways. Consider some of the possibilities for encoding relations of CONTACT, SUPPORT, and CONTAINMENT between two objects [Landau, 1996]. Four possible arrangements of a trajector (black) and landmark (brown) are shown Figure 5. Spanish uses a single word, en, for all of them. English uses one word, on, for the two situations in which CONTAINMENT does not enter in and another, in, for situations in which the trajector is (at least partially) contained in the landmark. German distinguishes two kinds of situations for which English uses on: auf when the landmark is under the trajector, an when the trajector is fixed to a vertical surface of the landmark. Korean distinguishes two kinds of CONTAINMENT (and CONTACT) situations, those in which the trajector fits tightly within the landmark, for which sok is used, and those in which there is loose fit, for which ahn is used.
But it is not languages which ``slice up'' the world in particular ways (languages don't actually ``do'' anything); it is people. In any case our goal is to model individual language learners, not the entire linguistic communities which embody particular languages. Descriptions of language and particular languages are useful to us only insofar as they give us clues about what people must learn to do in order to learn language.
Linguistic descriptions tell us that language is to a large extent about objects; thus a major task for language users and language learners is to find and categorize objects in the world. Within the visual-spatial world, they must be able to (1) segregate a scene into distinct regions associated with distinct objects, (2) cognitively ``bind'' together the features associated with each distinct object, and (3) assign these cognitive objects to the categories represented by the different nouns of the language. In Section 4.2.3 we discuss a mechanism which satisfies these basic constraints.
Linguistics also tells us that all languages have ways of explicitly encoding relations, so people must be able to find relations in the world and categorize them appropriately. Even if we assume that each scene contains only one salient relation, they must have the ability to (1) segregate a scene into distinct objects and bind their features together ((1) and (2) above), (2) cognitively bind together the relational features associated with a given candidate relation, (3) assign trajector and landmark status to the related objects, and (4) assign the cognitive representation of relations to the categories represented by the different relation terms of the language. We believe that these requirements point to an explicit way of representing relational information. Furthermore, since languages differ considerably in the sort of breakdown they make within the space of possible relations, the human capacity to represent and learn spatial relations must be a flexible one. Rather than a set of pre-existing relational categories, what is called for is a set of relational building blocks from which the relational categories of different languages can be assembled. In Section 4.2.4 we describe a representational scheme of this type.