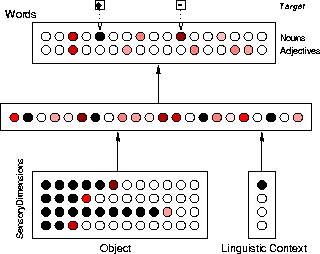
Figure  shows the network architecture. Each thin
arrow represents
complete connectivity between two layers of processing units. The
network is
designed to take objects and a linguistic context as inputs and
to produce a noun or adjective as output.
shows the network architecture. Each thin
arrow represents
complete connectivity between two layers of processing units. The
network is
designed to take objects and a linguistic context as inputs and
to produce a noun or adjective as output.
Inputs to the network are presented to two layers of processing units, one for the representation of the object itself and one for a linguistic context corresponding to a question the network is asked. Input objects consist of patterns of activation representing a perceptually present object in terms of a set of sensory dimensions. For the simulations discussed in this paper, the inputs are specified in terms of four or five dimensions. We require that the network learn to associate points along each dimension with particular words, so the simplest possible representation of a dimension, that is, a single unit, is excluded because it would only permit the association to different degrees of the dimension as a whole with each word. Therefore each dimension takes the form of a group of units in the input layer of the network. That is, input to the network along a given dimension consists of a vector of numbers, each between the minimum and maximum activation values of the units in the input layer of the network. There are several ways to represent dimensional input in the form of a vector, varying in the extent to which they make explicit the ordering of points along the dimension. At one extreme is a completely localized encoding, in which each dimensional vector contains one maximum value and the remainder of the numbers take on the minimum value. This form of encoding completely obscures ordering along the dimension because there is no correlation between the numbers in different positions in the vector (or the activations of units in each dimension group). At the other extreme is a ``thermometer'' encoding [HHL91]. In a thermometer representation, each of the positions in the vector corresponds to a point along a scale, and the value to be encoded normally falls between two of the positions. All of those positions to the ``right'' of this point take on their minimum values, the first position to the ``left'' of this point takes on an intermediate value, and all of the other leftward positions take on their maximum values.
: The Network. Each small circle is a processing unit, and each
rectangle a layer of processing units,
unconnected to each other.
An arrow represents complete connectivity between the units in two layers.
A possible input pattern and network response to it are shown, the degree
of shading of each unit representing its activation level.
The small squares at the top of the figure indicate the two targets
which the network receives for this pattern, one for the correct
response and one for an incorrect output above the network's response
threshold.
In this paper, we confine ourselves to thermometer
representations. In the networks used in the experiments reported here, each dimension
is represented by 12 units which have maximum activations of 1 and
minimum activations of 0.
So in the network, dimensional values of 3.3 and 8.8 along the scale
with maximum value of 12 would be
represented as the patterns [1, 1, 1, .3, 0, 0, 0, 0, 0, 0, 0, 0] and
[1, 1, 1, 1, 1, 1, 1, 1, .8, 0, 0, 0].
The figure illustrates a possible set of activations along each of the four
sensory dimensions for an input object.
In the networks used in the experiments reported here, each dimension
is represented by 12 units which have maximum activations of 1 and
minimum activations of 0.
So in the network, dimensional values of 3.3 and 8.8 along the scale
with maximum value of 12 would be
represented as the patterns [1, 1, 1, .3, 0, 0, 0, 0, 0, 0, 0, 0] and
[1, 1, 1, 1, 1, 1, 1, 1, .8, 0, 0, 0].
The figure illustrates a possible set of activations along each of the four
sensory dimensions for an input object.
The linguistic context input consists of a question of the form what size is it?, what color is it?, or what is it?, each question represented by a separate unit in the linguistic context layer of the network. (Four units are shown in the figure.) It is important to note that, because the network is given no actual syntactic context, the noun context ( what is it?) is indistinguishable from the adjective contexts ( what color is it?, etc.) at the start of training. In terms of the network's architecture, there are just several equally different linguistic context inputs that might be viewed as corresponding to noun, color, size, and texture. There is no hierarchical organization of the adjective terms in the architecture; that is, there is nothing that groups the adjectives as a class in opposition to the nouns.
Critically, from the perspective of the network, there is also no distinction between the input activation that corresponds to the object and that which corresponds to the question. From the network's point of view, there is just one input vector of 66 numbers jointly specifying an event in the world in terms of the five perceptual dimensions and the linguistic context input that co-occurs with the presentation of the object.
The hidden layer of the network compresses the
input patterns into a smaller set of units, 15 to 24 units in the
experiments we report here.
Thus at this level, the system no
longer has direct access to the input dimensions. This is an
important aspect of the architecture and an important theoretical
claim. It means that input dimensions that are distinct at input
are not (at least not without learning) represented separately.
This aspect of the architecture is based on considerable research
indicating that young children have difficulty attending
selectively to individual dimensions
[AS88]
and on our
past use of this architecture to model developmental changes in
selective attention to dimensions
[GS91,Smi93].
We will discuss more fully the wider implications
of this aspect of the network in the General Discussion.
The output layer consists of a single unit for each adjective and noun. A +1 activation on an output unit represents the network's labeling the input object with the corresponding word. A -1 activation represents the network's decision that the corresponding word is inappropriate for the input object, and a 0 activation represents an intermediate response, one that might be made if an object is described by the category but that is not an appropriate answer to the linguistic input question, for example, if ``red'' were the response to the question ``what is it?'' for a red dog.