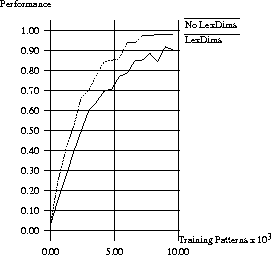
Figure  shows the results of this
experiment over 10 separate runs. There is an
advantage for words associated with specific lexical
dimensions
(
shows the results of this
experiment over 10 separate runs. There is an
advantage for words associated with specific lexical
dimensions
(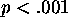 ). Thus, rather than adding complexity to the learning
task, linguistic input dimensions, in the absence of category
overlap, provide redundant information about category identity
that aids learning.
). Thus, rather than adding complexity to the learning
task, linguistic input dimensions, in the absence of category
overlap, provide redundant information about category identity
that aids learning.
: Experiment 4: Lexical Dimensions.
Performance is the proportion of test items for which the highest
overt response was correct.
Responses are averaged over 10 separate runs of the network.
The network again readily formed two ``syntactic'' categories presumably by associating the class of words for which there were no lexical dimensions in the linguistic context with the one linguistic context specifying that class. At the start of learning, the network's errors were distributed equally among the noun-like set and adjective-like set of outputs; the proportion of within class (above threshold) errors were .47 and .52 respectively. After 4000 trials, however, errors were predominantly from within the proper ``part of speech''; when the correct output was from the noun-like set, the network erred by responding with another item from that set .82 of the time and when the correct output was from adjective-like set, the network erred by responding with another item from that set .84 of the time. With these non-overlapping categories, the network also made within-dimension errors for the adjectives. These were .18 at the start of learning and .86 after 4000 trials.
The principal result from this simulation is that, all other things being equal, learning subcategories of associated questions and responses provides an advantage.