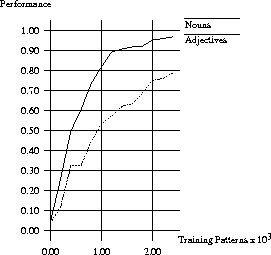
Figure  shows the learning rates for adjectives and
nouns in this experiment.
The data shown are averages over 10 runs
with different initial random weights on the network's connections.
The smaller and more compactly shaped noun categories are learned much
faster than the larger and more slab-like adjective
categories (
shows the learning rates for adjectives and
nouns in this experiment.
The data shown are averages over 10 runs
with different initial random weights on the network's connections.
The smaller and more compactly shaped noun categories are learned much
faster than the larger and more slab-like adjective
categories (
 ). Performance on the nouns is close to perfect by the 2000th
training trial. Performance on the adjectives continues to improve,
but never reaches the level of the nouns.
). Performance on the nouns is close to perfect by the 2000th
training trial. Performance on the adjectives continues to improve,
but never reaches the level of the nouns.
: Experiment 1: Nouns vs. Adjectives.
Performance is the proportion of test items for which the highest
overt response was correct.
Responses are averaged over 10 separate runs of the network.
We also asked whether in learning these categories, the network showed any implicit knowledge of lexical categories. First, does the network develop a distinction between nouns and adjectives as a class? Second, does the network develop a distinction between different dimensional terms, analogous to knowing, for example, that wet and dry are attributes of one kind and that rough and smooth are attributes of another kind? These are important questions because children show clear evidence of the first distinction in their early errors but not the second distinction (see Carey, 1994; Smith, 1984; Smith & Sera, 1992; but see Backscheider & Shatz, 1993).
To answer the first question, we defined ``within-part-of-speech errors'' as the proportion of cases with an incorrect response (above threshold) for which the response was the correct ``part of speech'' (adjective or noun). Table 2 shows the proportion of within- and between-part-of-speech errors at the start of learning and after 1000 training trials. At the start of learning when the network knows nothing, the relative frequency of noun and adjective responses (2:1) corresponds to the relative number of noun and adjective output units (2:1) and is unrelated to the linguistic context input. However, as learning progresses, the character of the error becomes associated with the linguistic input that specifies the class of possible answers. After 1000 training trials, when the network still has not yet fully acquired the adjective terms, the network shows implicit knowledge that all the adjectives form a class.

Table 2: Experiment 1: Within- and Between-Part-of-Speech
Errors.
Figures represent the
proportion of incorrect overt responses in different part-of-speech
categories.
To answer the second question, we defined ``within-dimension errors'' as the proportion of cases in which adjective questions received incorrect adjective responses and the response was on the right dimension. Noun questions and noun responses to adjective questions did not contribute to this measure. At the start of training, such within-dimension errors were rare, occurring .08 of the time. The frequency of within-category errors increased with training, reaching a maximum of .23 of the time after 2000 trials. Thus the network shows little implicit knowledge of which terms refer to attributes on the same dimension.