R. Port, Q500, Intro to Cognitive Science - Sean McLennan subbing
Nov. 1/99
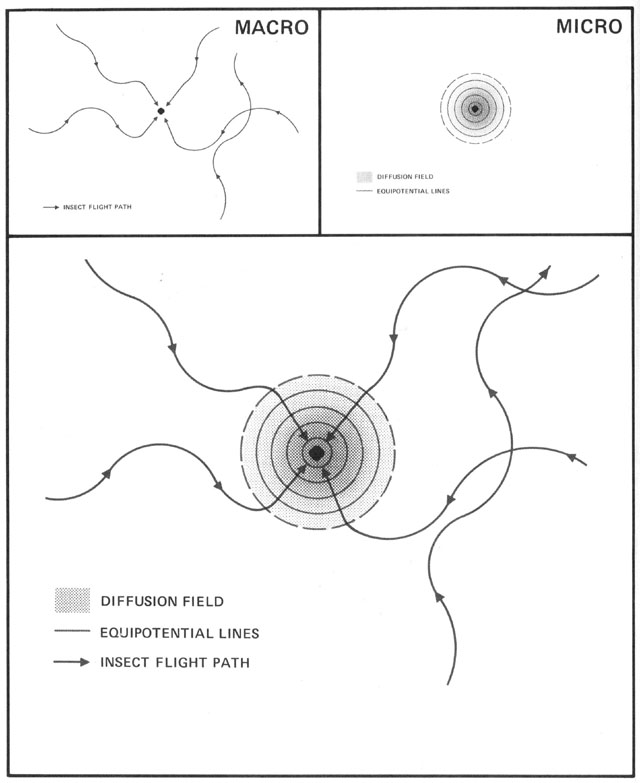
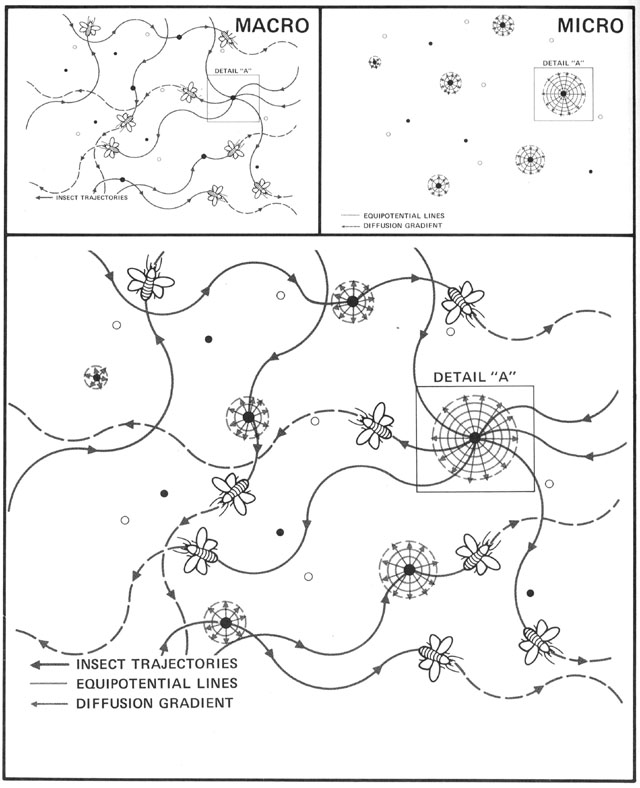
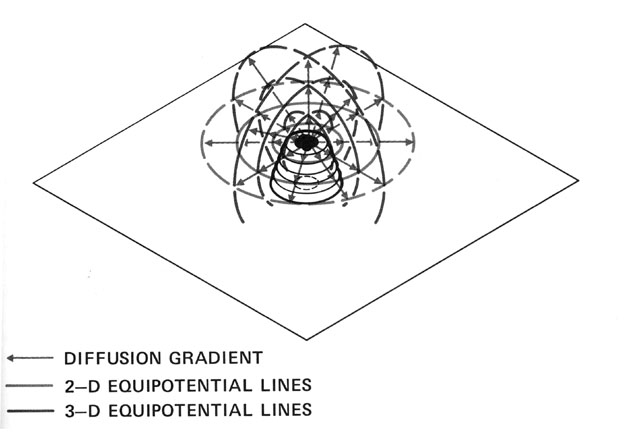
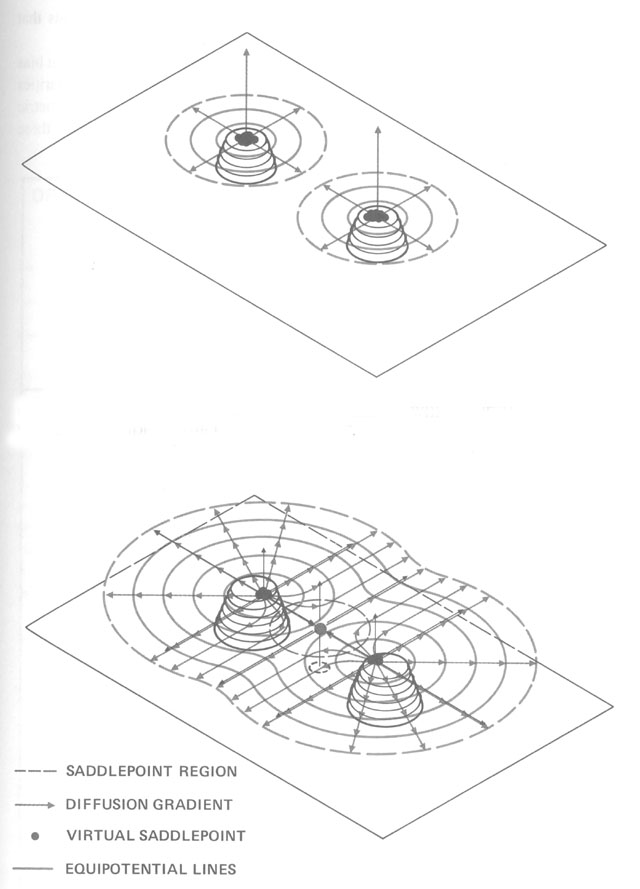
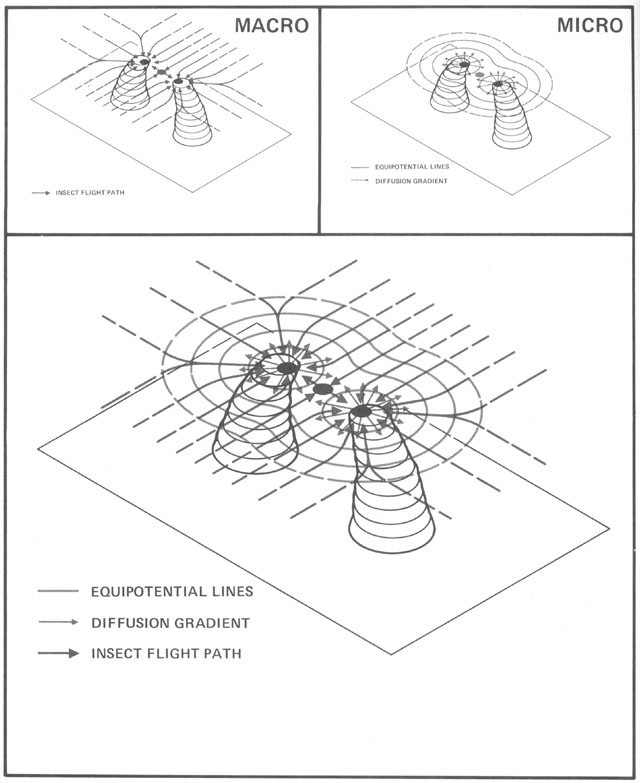
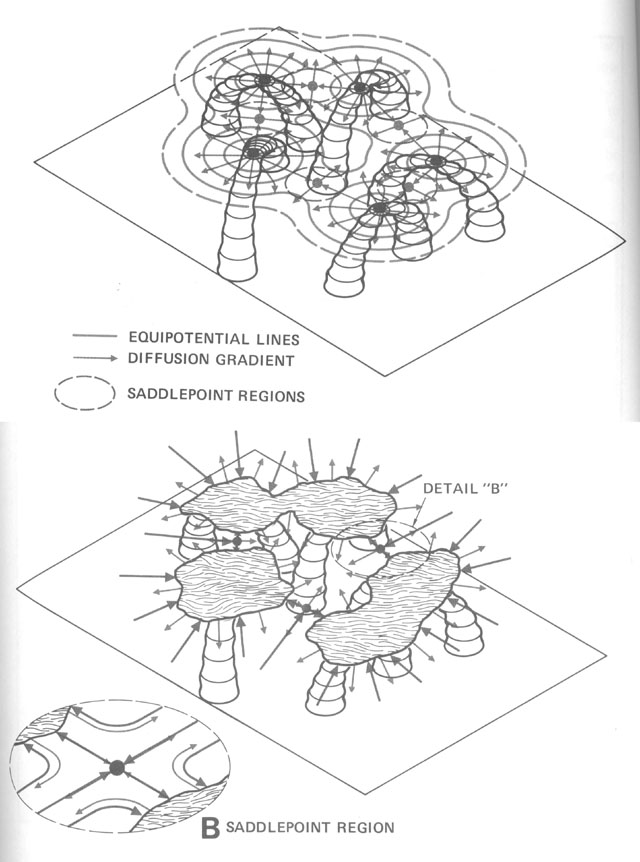
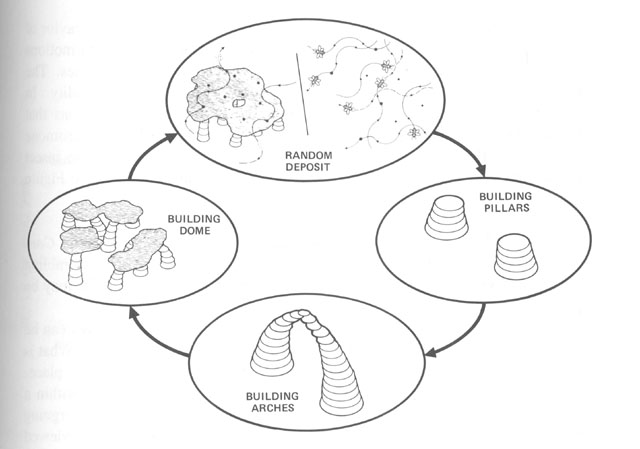
Without centralized control and detailed knowledge of architecture and physics, how can termites build their nests? (Figures from Kugler & Turvey - pgs 69-89)
Begining with randomness (flight paths, deposit sites), based on simple rules (deposit in location
of highest pheremone concentration), and basic physics (diffusion of pheremones), a complex structure
emerges
For the most part, "Emergence" is a blanket term (somewhat of a buzzword) that encompasses an enormous range of phenomena. It has also been called "self-organization".
The fact that self-organization / emergence seems to contradict the second law of thermodynamics (entropy) which states that over time there is a tendency for systems to lose energy and complexity, has long been recognized. First was Spencer, a contemporary of Darwin, discussion life and evolution as a contradiction to entropy. Others (Doyne Farmer, Chris Langton) have gone so far as to claim that emergence is a weak-force of the universe on par with entropy. Chris Langton uses his "lambda" function (seen in our CA lab) as a definition of where emergence counteracts entropy.
Examples of Emergent Phenomena:
Emergent phenomena literally pervade every aspect of our daily lives
There are a few things that seem common to all emergent phenomena:
It also seems possible to define two different type of emergent phenomena, direct vs. indirect.
Direct emergence is more causative; for example a thermometer. That it can act as a measure of temperature
is an emergent phenomenon, but the two factors, temperature and volume of mercury/alcohol, are coupled in
a causative relationship. Other examples: traffic jams, sunflowers following the sun, planetary orbits, analog computers.
Indirect emergence is mediated by learned behaviour (evolutionarily or otherwise). So pheremones do not
move mud and cannot create a termite mound themselves.
Emergence is a very difficult thing to study because of its pervasiveness. Some believe that it is impossible to study, and believe that there are no fundamental, underlying rules that govern it. Of course, others disagree.
The primary method of study to this point has been through:
Kugler, Peter and Michael Turvey. 1987. Information, Natural Law, and the Self-assembly of Rhythmic Movement. Hillsdale, NJ: Lawrence Erbaum Associates.
Holland, John. 1995. Hidden Order. Reading, MA: Helix Books
Holland, John. 1998. Emergence. Reading, MA: Helix Books
Levy, Steven. 1992. Artificial Life.New York: Vintage Books
The following site has an excellent visual tutorial of GAs.
http://cs.felk.cvut.cz/~xobitko/ga/
Schemata are essentially similarity templates that describe a set of chromosomes that share values in certain positions. To describe a schema we must add the wildcard “*” to our string notation. Thus, the schema *0 describes a subset of 2 chromosomes: {10, 00}; 1** describes the subset {100, 101, 110, 111}, etc. Of course, schemata with no *’s describe sets of 1 element — i.e. the notion of schemata subsumes individual chromosomes.
The total number of possible schemata given a chromosome length of l is 3^l since there are three possibilities at each position: 1, 0, or *. The chromosomes, whose values are set, are instantiations of 2^l schemata since each position may take its actual value or the wildcard. To see this, let’s examine an example of a short chromosome length, l = 3, for which there are 3^3 = 27 possible schemata. The chromosome 101 is an instantiation of 2^3 = 8 of those 27 schemata: {***, 1**, *0*, **1, 10*, 1*1, *01, 101}.
The important insight is that a single chromosome, in fact, also represents a great number more schemat a — i.e. categories — and thus in some sense, by judging the fitness of that individual, the fitness of each category is also judged. By the same token, the fitness of an individual chromosome is also in a sense a function of the fitnesses of each schema it represents. The fitness of a schema is defined as the average of the fitnesses of all instantiations of that schema in the populat ion. Although this figure is never explicitly calculated in a GA it is implicitly calculated because individual chromosomes are members of a population. It can therefore be seen that in the process of selection, not only are relatively fit individuals selected and mated, but also relatively fit schemata.
Schemata, themselves, can be thought of as instantiations of other schemata. For example, *1**1* is as much an instantiation of ***1* and *1*** as the chromosome 010010. Thus, ***1* and *1*** can be regarded as “building blocks” of *1**1*. Let’s say that *1**1* is a solution to a given problem and any chromosome instantiating that schema would be evaluated as 100% fit. Chromosomes that are instantiations of *1*** and ***1* (but not *1**1*) and thus contain building blocks of the target schema would be evaluated with relatively high fitnesses, 50% say, increasing the likelihood they will be mated together. This in turn increases the likelihood that their building blocks will be combined to evolve the target solution.
Taken in a slightly different light, schemata can be thought of as hypotheses. The string 101 makes 8 implicit “hypotheses” about the solution to the problem; that a 1 in the first position is important to the solution; that a zero in the second position is important to the solutions; that a 1 in the first position and a zero in the second position is important to the solution; etc. The merit of those hypotheses is rated by the fitness function and by comparing the similarities between the chromosomes that have the highest ratings, the hypotheses with the greatest merit eventually emerge.
Implicit parallelism — this power to judge many categories by judging a single member — is the primary power of the GA. One chromosome implicitly represents a number of schemata, and a single evaluation of that chromosome implicitly evaluates all the associated schemata. In the process of crossover and mutation, relatively short schemata are not disrupted and are allowed to propagate through the population from generation to generation, guiding the search through solution space.
The following summarizes the major points of Schema Threorem:
Holland, John. (1975). Adaption in Natural and Artificial Systems. Ann Arbor, MI: University of Michigan Press.
Holland, John. 1995. Hidden Order. Reading, MA: Helix Books
Mitchell, Melanie. (1996). An Introduction to Genetic Algorithms. Cambridge, MA: MIT Press.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}