


Stimuli for this experiment were generated analogously to
those in Experiment 1. There were two types of categories, those
which spanned relatively wide regions of the space of all
possible input objects and those which spanned relatively narrow
regions. Both the Small set and the Large set contained 18 words.
In the Small set, each word was defined in terms of a range of
1/6 of the possible values along each input dimension. Thus the
extension of each of these categories covered 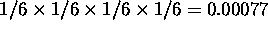 of the space of possible inputs.
In the Large set, each word was defined in terms of a range of
1/3 of the possible values along each input dimension, a total of
of the space of possible inputs.
In the Large set, each word was defined in terms of a range of
1/3 of the possible values along each input dimension, a total of
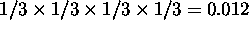 of the space of
possible objects, that is, 16 times the size of the region occupied by the
extension of each of the categories in the Small set. Note that
the volumes of the two sets are closer than in the first
experiment. The Large and Small categories overlapped in the
space of all possible categories. Two linguistic context inputs were used
to signal the relevant kind of category, one for which the
Large-volume words were appropriate responses, the other for
which the Small-volume words were appropriate responses. Given
the relatively simpler learning task with fewer overlapping
categories, we tested the network after every 500 training
trials.
of the space of
possible objects, that is, 16 times the size of the region occupied by the
extension of each of the categories in the Small set. Note that
the volumes of the two sets are closer than in the first
experiment. The Large and Small categories overlapped in the
space of all possible categories. Two linguistic context inputs were used
to signal the relevant kind of category, one for which the
Large-volume words were appropriate responses, the other for
which the Small-volume words were appropriate responses. Given
the relatively simpler learning task with fewer overlapping
categories, we tested the network after every 500 training
trials.