


The input to the network consisted of an object described on
five perceptual dimensions and the question accompanying the object.
The input objects were instances of 30 possible categories.
Each input object had a value for each of the five perceptual
dimensions, and
each category was defined in terms of the range of values that its
instances could take along each of the dimensions.
Twenty of these categories were
organized to be noun-like and 10 were organized to be adjective-like.
Each noun was defined in terms of a range of 1/10 of the
possible values along each of the five input sensory dimensions.
Each adjective category was defined in terms of a range of 1/5 of
the possible values along one of the input dimensions and any
value along the other four. Thus each noun spanned  of the multi-dimensional space of all possible categories
whereas each adjective spanned
of the multi-dimensional space of all possible categories
whereas each adjective spanned 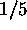 of the space.
Table 1 shows ranges of possible values on the five dimensions for two
of the noun and three of the adjective categories.
Note that the noun categories may overlap on one or more dimensions
(dimensions 2 and 5 in the example categories).
No noun categories overlap completely, however.
This is not so for the adjective categories.
In Table 1, adjective 1 overlaps with both adjective 2 and 3 because it is
possible to create an object which is an instance of both adjective 1 and
adjective 2 or both adjective 1 and adjective 3.
of the space.
Table 1 shows ranges of possible values on the five dimensions for two
of the noun and three of the adjective categories.
Note that the noun categories may overlap on one or more dimensions
(dimensions 2 and 5 in the example categories).
No noun categories overlap completely, however.
This is not so for the adjective categories.
In Table 1, adjective 1 overlaps with both adjective 2 and 3 because it is
possible to create an object which is an instance of both adjective 1 and
adjective 2 or both adjective 1 and adjective 3.
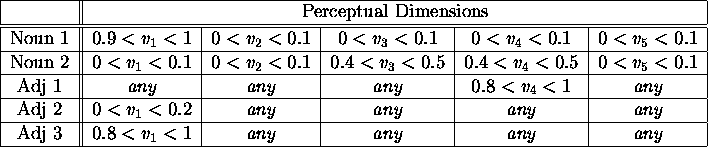
Table 1: Experiment 1: Ranges of Values on Perceptual Dimensions for
5 Input Objects.
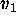 , etc. represent the values on the five dimensions.
Each range is expressed in terms of proportions of the distance from the
minimum to the maximum value.
, etc. represent the values on the five dimensions.
Each range is expressed in terms of proportions of the distance from the
minimum to the maximum value.
The ten adjective categories were organized into five lexical
dimensions by association with the specific input dimension whose
values were constrained within the adjective category and by
association with a specific linguistic context input, e.g.,
``what size is it?''
Thus the ten
adjectives were structured into five dimensions each with two
contrasting terms. In Table 1, adjectives 2 and 3 belong to the same lexical dimension.
In Table 1, adjectives 2 and 3 belong to the same lexical dimension.
For each training instance, the inputs were generated as follows. First an output category was selected at random from the set of 30 possible outputs (the 20 nouns and the 10 adjectives). The selection of the relevant output determined the linguistic context input. Then for each of the five perceptual dimensions, a possible value was picked at random consistent with the selected output.
The linguistic context input consisted of the pattern representing a question that would be appropriate for the selected category, each question corresponding to a lexical dimension. For example, if the category was big, the input unit representing what size it is? was turned on (that is, its output was set to 1.0), and the other linguistic context units were turned off. If the category was dog, the input unit representing what is it? was turned on, and the other linguistic context units were turned off.
Because there was randomness in the selection of output categories and corresponding input objects, because the input objects varied continuously, and because the targets depended in part on the network's response, the network was never trained more than once on a particular input-target pair.